The quantum world is mind-bogglingly weird
No matter how hard physicists probe, they still puzzle over this, the universe's deepest secret

The quantum world is the world that’s smaller than an atom. Things at this scale don’t behave the same way as objects on the scale that we can see.
EzumelImages/iStockphoto
If you’re interested in the smallest things known to scientists, there’s something you should know. They are extraordinarily ill-behaved. But that’s to be expected. Their home is the quantum world.
These subatomic bits of matter don’t follow the same rules as objects that we can see, feel or hold. These entities are ghostly and strange. Sometimes, they behave like clumps of matter. Think of them as subatomic baseballs. They also can spread out as waves, like ripples on a pond.
Although they might be found anywhere, the certainty of finding one of these particles in any particular place is zero. Scientists can predict where they might be — yet they never know where they are. (That’s different than, say, a baseball. If you leave it under your bed, you know it’s there and that it will stay there until you move it.)

“The bottom line is, the quantum world just doesn’t work in the way the world around us works,” says David Lindley. “We don’t really have the concepts to deal with it,” he says. Trained as a physicist, Lindley now writes books about science (including quantum science) from his home in Virginia.
Here’s a taste of that weirdness: If you hit a baseball over a pond, it sails through the air to land on the other shore. If you drop a baseball in a pond, waves ripple away in growing circles. Those waves eventually reach the other side. In both cases, something travels from one place to another. But the baseball and the waves move differently. A baseball doesn’t ripple or form peaks and valleys as it travels from one place to the next. Waves do.
But in experiments, particles in the subatomic world sometimes travel like waves. And they sometimes travel like particles. Why the tiniest laws of nature work that way isn’t clear — to anyone.
Consider photons. These are the particles that make up light and radiation. They’re tiny packets of energy. Centuries ago, scientists believed light traveled as a stream of particles, like a flow of tiny bright balls. Then, 200 years ago, experiments demonstrated that light could travel as waves. A hundred years after that, newer experiments showed light could sometimes act like waves, and sometimes act like particles, called photons. Those findings caused a lot of confusion. And arguments. And headaches.
Wave or particle? Neither or both? Some scientists even offered a compromise, using the word “wavicle.” How scientists answer the question will depend on how they try to measure photons. It’s possible to set up experiments where photons behave like particles, and others where they behave like waves. But it’s impossible to measure them as waves and particles at the same time.

This is one of the bizarre ideas that pops out of quantum theory. Photons don’t change. So how scientists study them shouldn’t matter. They shouldn’t only see a particle when they look for particles, and only see waves when they look for waves.
“Do you really believe the moon exists only when you look at it?” Albert Einstein famously asked. (Einstein, born in Germany, played an important role in developing quantum theory.)
This problem, it turns out, is not limited to photons. It extends to electrons and protons and other particles as small or smaller than atoms. Every elementary particle has properties of both a wave and a particle. That idea is called wave-particle duality. It’s one of the biggest mysteries in the study of the smallest parts of the universe. That’s the field known as quantum physics.
Quantum physics will play an important role in future technologies — in computers, for example. Ordinary computers run calculations using trillions of switches built into microchips. Those switches are either “on” or “off.” A quantum computer, however, uses atoms or subatomic particles for its calculations. Because such a particle can be more than one thing at the same time — at least until it’s measured — it may be “on” or “off” or somewhere in-between. That means quantum computers can run many calculations at the same time. They have the potential to be thousands of times faster than today’s fastest machines.
IBM and Google, two major technology companies, are already developing superfast quantum computers. IBM even allows people outside the company to run experiments on its quantum computer.
Experiments based on quantum knowledge have produced astonishing results. For example, in 2001, physicists at Harvard University, in Cambridge, Mass., showed how to stop light in its tracks. And since the mid-1990s, physicists have found bizarre new states of matter that were predicted by quantum theory. One of those — called a Bose-Einstein condensate — forms only near absolute zero. (That’s equivalent to –273.15° Celsius, or –459.67° Fahrenheit.) In this state, atoms lose their individuality. Suddenly, the group acts as one big mega-atom.
Quantum physics isn’t just a cool and quirky discovery, though. It’s a body of knowledge that will change in unexpected ways how we see our universe — and interact with it.
A quantum recipe
Quantum theory describes the behavior of things — particles or energy — on the smallest scale. In addition to wavicles, it predicts that a particle may be found in many places at the same time. Or it may tunnel through walls. (Imagine if you could do that!) If you measure a photon’s location, you might find it in one place — and you might find it somewhere else. You can never know for certain where it is.
Also weird: Thanks to quantum theory, scientists have shown how pairs of particles can be linked — even if they’re on different sides of the room or opposite sides of the universe. Particles connected in this way are said to be entangled. So far, scientists have been able to entangle photons that were 1,200 kilometers (750 miles) apart. Now they want to stretch the proven entanglement limit even farther.
Quantum theory thrills scientists — even as it frustrates them.
It thrills them because it works. Experiments verify the accuracy of quantum predictions. It also has been important to technology for more than a century. Engineers used their discoveries about photon behavior to build lasers. And knowledge about the quantum behavior of electrons led to the invention of transistors. That made possible modern devices such as laptops and smartphones.
But when engineers build these devices, they do so following rules that they don’t fully understand. Quantum theory is like a recipe. If you have the ingredients and follow the steps, you end up with a meal. But using quantum theory to build technology is like following a recipe without knowing how food changes as it cooks. Sure, you can put together a good meal. But you couldn’t explain exactly what happened to all of the ingredients to make that food taste so great.
Scientists use these ideas “without any idea of why they should be there,” notes physicist Alessandro Fedrizzi. He designs experiments to test quantum theory at Heriot-Watt University in Edinburgh, Scotland. He hopes those experiments will help physicists understand why particles act so strangely on the smallest scales.
Is the cat okay?

If quantum theory sounds strange to you, don’t worry. You’re in good company. Even famous physicists scratch their heads over it.
Remember Einstein, the German genius? He helped describe quantum theory. And he often said he didn’t like it. He argued about it with other scientists for decades.
“If you can think about quantum theory without getting dizzy, you don’t get it,” Danish physicist Niels Bohr once wrote. Bohr was another pioneer in the field. He had famous arguments with Einstein about how to understand quantum theory. Bohr was one of the first people to describe the weird things that pop out of quantum theory.
“I think I can safely say that nobody understands quantum [theory],” noted American physicist Richard Feynman once said. And yet his work in the 1960s helped show that quantum behaviors aren’t science fiction. They really happen. Experiments can demonstrate this.
Quantum theory is a theory, which in this case means it represents scientists’ best idea about how the subatomic world works. It’s not a hunch, or a guess. In fact, it’s based on good evidence. Scientists have been studying and using quantum theory for a century. To help describe it, they sometimes use thought experiments. (Such research is known as theoretical.)
In 1935, Austrian physicist Erwin Schrödinger described such a thought experiment about a cat. First, he imagined a sealed box with a cat inside. He imagined the box also contained a device that could release a poison gas. If released, that gas would kill the cat. And the probability the device released the gas was 50 percent. (That’s the same as the chance that a flipped coin would turn up heads.)
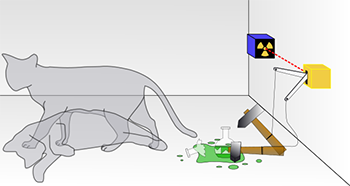
To check the status of the cat, you open the box.
The cat is either alive or dead. But if cats behaved like quantum particles, the story would be stranger. A photon, for instance, can be a particle and a wave. Likewise, Schrödinger’s cat can be alive and dead at the same time in this thought experiment. Physicists call this “superposition.” Here, the cat won’t be one or the other, dead or alive, until someone opens the box and takes a look. The fate of the cat, then, will depend on the act of doing the experiment.
Schrödinger used that thought experiment to illustrate a huge problem. Why should the way that the quantum world behaves depend on whether someone is watching?
Welcome to the multiverse
Anthony Leggett has been thinking about this problem for 50 years. He’s a physicist at the University of Illinois at Urbana-Champaign. In 2003, he won a Nobel Prize in physics, the most prestigious award in his field. Leggett has helped develop ways to test quantum theory. He wants to know why the smallest world doesn’t match with the ordinary one we see. He likes to call his work “building Schrödinger’s cat in the laboratory.”
Leggett sees two ways to explain the problem of the cat. One way is to assume that quantum theory will eventually fail in some experiments. “Something will happen that is not described in the standard textbooks,” he says. (He has no idea what that something might be.)
The other possibility, he says, is more interesting. As scientists conduct quantum experiments on larger groups of particles, the theory will hold. And those experiments will unveil new aspects of quantum theory. Scientists will learn how their equations describe reality and be able to fill in the missing pieces. Eventually, they will be able to see more of the whole picture.

Simply put, Leggett hopes: “Things that right now seem fantastic will be possible.”
Some physicists have proposed even wilder solutions to the “cat” problem. For example: Maybe our world is one of many. It’s possible that infinitely many worlds exist. If true, then in the thought experiment, Schrödinger’s cat would be alive in half the worlds — and dead in the rest.
Quantum theory describes particles like that cat. They may be one thing or another at the same time. And it gets weirder: Quantum theory also predicts that particles may be found in more than one place at a time. If the many-world idea is true, then a particle might be in one place in this world, and somewhere else in other worlds.
This morning, you probably chose which shirt to wear and what to eat for breakfast. But according to the many worlds idea, there is another world where you made different choices.
This weird idea is called the “many-world” interpretation of quantum mechanics. It is exciting to think about, but physicists have not found a way to test whether it’s true.
Tangled up in particles
Quantum theory includes other fantastic ideas. Like that entanglement. Particles may be entangled — or connected — even if they’re separated by the width of the universe.
Imagine, for instance, that you and a friend had two coins with a seemingly magical connection. If one showed up heads, the other would always be tails. You each take your coins home and then flip them at the same time. If yours comes up heads, then at the exact same moment you know your friend’s coin has just come up tails.
Entangled particles work like those coins. In the lab, a physicist can entangle two photons, then send one of the pair to a lab in a different city. If she measures something about the photon in her lab — such as how fast it moves — then she immediately knows the same information about the other photon. The two particles behave as though they send signals instantaneously. And this will hold even if those particles are now separated by hundreds of kilometers.
Story continues below video.
As in other parts of quantum theory, that idea causes a big problem. If entangled things send signals to each other instantly, then the message might seem to travel faster than the speed of light — which, of course, is the speed limit of the universe! So that cannot happen.
In June, scientists in China reported a new record for entanglement. They used a satellite to entangle six million pairs of photons. The satellite beamed the photons to the ground, sending one of each pair to one of two labs. The labs sat 1,200 kilometers (750 miles) apart. And each pair of particles remained entangled, the researchers showed. When they measured one of a pair, the other one was affected immediately. They published those findings in Science.
Scientists and engineers are now working on ways to use entanglement to link particles over ever-longer distances. But the rules of physics still prevent them from sending signals faster than the speed of light.
Why bother?
If you ask a physicist what a subatomic particle really, truly is, “I don’t know that anyone can give you an answer,” says Lindley.
Many physicists are content with not knowing. They work with quantum theory, even though they don’t understand it. They follow the recipe, never quite knowing why it works. They may decide that if it works, why bother going any further?
Others, like Fedrizzi and Leggett, want to know why particles are so weird. “It’s far more important to me to find out what’s behind all of this,” Fedrizzi says.
Forty years ago, scientists were skeptical that they could do such experiments, notes Leggett. Many thought that asking questions about the meaning of quantum theory was a waste of time. They even had a refrain: “Shut up and calculate!”
Leggett compares that past situation to exploring sewers. Going into sewer tunnels might be interesting but not worth visiting more than once.
“If you were to spend all your time rummaging around in the bowels of the Earth, people would think you were rather strange,” he says. “If you spend all your time on the foundations of quantum [theory], people will think you’re a little odd.”
Now, he says, “the pendulum has swung the other way.” Studying quantum theory has become respectable again. Indeed, for many it has become a lifelong quest to understand the secrets of the tiniest world.
“Once the subject hooks you, it won’t let you go,” says Lindley. He, by the way, is hooked.






